微信公众号信息采集思路与实践
项目背景
早在两年前就进行了微信公众号基本信息采集
https://github.com/DropsOfZut/awesome-security-weixin-official-accounts/commits/master
通过一篇公众号文章获取爬取公众号基本信息
存在问题:更新麻烦、文章存在失效、信息处理麻烦
想要的功能:方便git仓库同步,方面增加删除公众号
另外
微信公众号相对封闭不易爬取
关于安全方面的文章微信公众号也是一个重要来源
舆情监测分析、公众号数据分析
爬取一个公众号的来源从哪里?
普通数据的爬取方式,给一个网站,从头爬取链接,链接爬详情。
微信官方是没有这样的一个网站
只有寻找蹊径
爬取方式
- 方案一:基于搜狗入口
- 方案二:网页微信端
- 方案三:对微信进行中间人攻击
- 方案四:Hook微信
0x01基于搜狗入口
一般流程:
1、搜狗微信搜索入口进行公众号搜索
2、选取公众号进入公众号历史文章列表
3、对文章内容进行解析入库
采集过于频繁的话,搜狗搜索和公众号历史文章列表访问都会出现验证码。直接采用一般的脚本采集是无法拿到验证码的。这里可以使用无头浏览器来进行访问,通过对接打码平台识别验证码。无头浏览器可采用selenium。
即便采用无头浏览器同样存在问题:
1、效率低下(实际上就是在跑一个完整的浏览器来模拟人类操作)
2、网页资源浏览器加载难以控制,脚本对浏览器加载很难控制 3、验证码识别也无法做到100%,中途很可能会打断抓取流程
如果坚持使用搜狗入口并想进行完美采集的话只有增加代理IP。顺便说一句,公开免费的IP地址就别想了,非常不稳定,而且基本都被微信给封了。
除了面临搜狗/微信的反爬虫机制之外,采用此方案还有其他的缺点:
无法获得阅读数、点赞数等用于评估文章质量的关键信息
无法及时获得已经发布公众号文章,只能作定期的重复爬取 只能获得最近十条群发文章
github免费轮子:
0x02网页微信端
微信聊天不仅有手机端、电脑端还有web端https://wx.qq.com/
扫码登录微信、此时数据传输走的就是https。
通过抓取数据包、模拟分析。能完成微信上大部分操作。
群发消息、获取消息、删除好友、获取公众号信息
被动爬取与主动爬取
不要重复做轮子:pychat与itchat
基本请求功能都有封装,它实现的原理就是对网页微信进行抓包分析,汇总成个人微信接口,目标就是所有网页微信能实现的功能它都能实现
这种方案的主要流程是:
1、服务器端通过ItChat登录网页微信
2、当公众号发布新文章推送的时候,会被服务端截获进行后续的解析入库
这种方案的优点是:
1、基本零间隔获取已经发布的公众号文章
2、能获取点赞数、阅读数
3、只需手机微信保持登陆,不用其他操作
网页版微信存在问题:
1、新注册的小号已经不能登入
2、对老号也有部分限制
3、itchat已经不支持微信公众号的获取了
4、必须有手机在线、不能主动退出或长时间断网掉线
0x03 对微信进行中间人攻击
中间人攻击本是某种黑客手法,用于截取客户端与服务端之间的通信信息。这种方案的思路是在手机微信和微信服务器之间搭建一个”HTTPS代理”,用于截获手机微信获取的公众号文章信息。
一般性步骤是:
1、手机微信搜索一个公众号
2、点击进入公众号历史文章页面
3、代理识别已经进入列表页,进行内容截获,同时根据实际情况返回继续下拉或爬取新的公众号的js代码
这种方案能够实现自动化的原因是:
1、微信公众号使用的是HTTPS协议,且内容未加密
2、微信公众号文章列表和详情本质上是个Web页面,可以嵌入js代码进行控制
这种方案的优点:
1、一般情况下不会被屏蔽
2、能拿到点赞数和阅读数等文章评估信息 3、能拿到公众号全部的历史文章
当然,也存在很多缺点:
1、需要一个长期联网的实体手机
2、前期需要设置代理,工作量比较大
3、本质上还是个轮查的过程,而不是实时推送
4、同样有Web加载难以控制的风险,且本地网络环境对其影响非常大
5、存在着微信接口发生变更代码不再适应的情况
利用Mimtproxy实现过程
常用的代理抓包工具;Wireshark、BP、Mimtproxy、Anyproxy、Fidder
使用Mimtproxy正向中间人代理,部署在与设备同一局域网下进行拦截数据,数据请求先流向代理、代理发送到服务器、得到响应、返回给设备
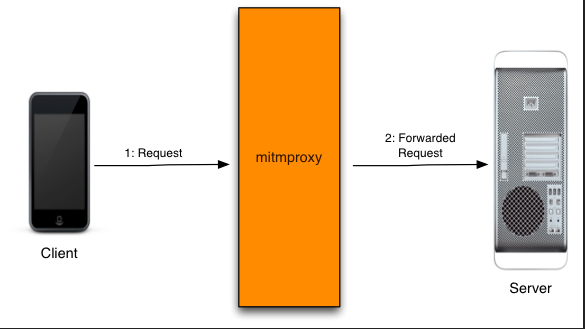
目前比较广泛的应用是做仿真爬虫,即利用手机模拟器、无头浏览器来爬取 APP 或网站的数据,mitmpproxy 作为代理可以拦截、存储爬虫获取到的数据,或修改数据调整爬虫的行为。
最强功能,拿到数据包可进行二次开发(python语言)
快速上手一: 获取数据流
1 | import mitmproxy.http |
2 | from mitmproxy import ctx |
3 | |
4 | num = 0 |
5 | |
6 | |
7 | def request(flow: mitmproxy.http.HTTPFlow): |
8 | global num |
9 | num = num + 1 |
10 | ctx.log.info("We've seen %d flows" % num) |
快速上手二: 事件获取数据流
1 | import mitmproxy.http |
2 | from mitmproxy import ctx |
3 | |
4 | |
5 | class Counter: |
6 | def __init__(self): |
7 | self.num = 0 |
8 | |
9 | def request(self, flow: mitmproxy.http.HTTPFlow): |
10 | self.num = self.num + 1 |
11 | ctx.log.info("We've seen %d flows" % self.num) |
12 | |
13 | |
14 | addons = [ |
15 | Counter() |
16 | ] |
请求web可视化界面展示
手动点击手机微信公众号文章,流量经过mimtproxy代理,在web端中能看到流量信息。明文展示。同时更多的信息也存在如:点赞、喜欢、阅读数。
点击刷新公众号主页与历史文章,获取公众号的基本信息,与历史文章的连接。
如何自动化?
设计一个公众号文章自动化爬取。
首先获取公众号的历史文章链接、再爬取链接获取详情页。但是不能自动化,就是说现在必须手动点击。才能获取数据。
之前说了仿真爬虫修改数据调整爬虫的行为。我们可以通过修改响应包中的内容,加入自动翻页的js。
实现10秒之后自动跳转到下个url
1 | <script> |
2 | setTimeout(function(){{window.location.href='{url}';}},10); |
3 | </script> |
代替了我们手动点击下一个内容的请求。我么在返回的数据中注入上面的js,同时连接放入下一个请求的链接。周而复始。
注意:必须有一个手机端发送的起始请求。在断网情况下,将不能继续自动化。
整体架构图
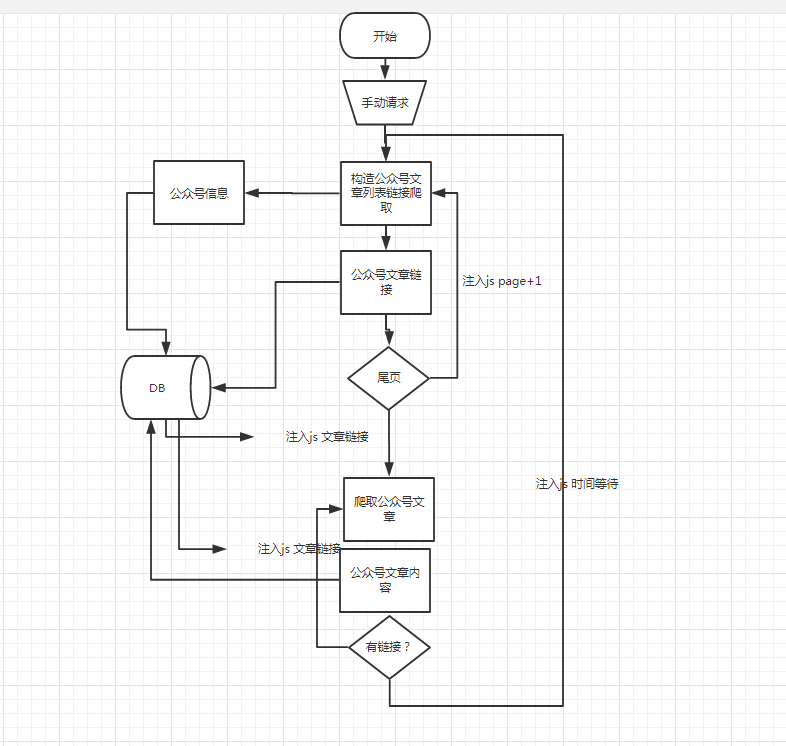
1、 需要一个公众号的id
2、 构造模拟请求历史文章列表的请求,手动发送(参数变化id)
3、 首页能获取到公众号的详情信息、存储到数据库
4、 获取到所有的公众号文章的链接、存储到数据库
5、 下页的公众号的历史数据通过注入js如page+1让程序自动爬取
6、 最后一页的返回公众号数据通过注入js如放入公众号文章的链接
7、 获取到公众号文章的数据、解析各种参数、存储数据库
8、 下页的公众号文章数据注入js如公众号文章链接
9、 最后一页的返回公众号文章数据注入js如:等待时间后重新执行2
这样完成持续监听,主动获取。
0x04 Hook微信
借助微信hook,拦截修改某些call,填充进我们的Python代码,进行微信公众号文章的爬取
实现hook功能,申请内存,修改call,在里面写调用python逻辑
使用vs桌面应用c调动python程序
限制:每个版本的微信call偏移量不同。
优点:被动获取,请求量较少。
属于逆向方面的知识,还需要调用c、修改ddl。
找群里大神修改好的,直接用。