在写观星资产扫描器的时候,IP定位用的是Geoip提供的IP库实现的,每个用户在使用扫描器的时候如果本地没有IP库需要从远端进行下载,然而这个文件将近50M,为尽量减少下载的效率,采用断点续传。
断点续传就是在上传或者下载的时候,出现网络状况,可以从已经上传或下载的部分开始继续上传下载未完成的部分,而没有必要从头开始上传下载。用户可以节省时间,提高速度。
为简单明了的表达自己的意思,画了个流程图
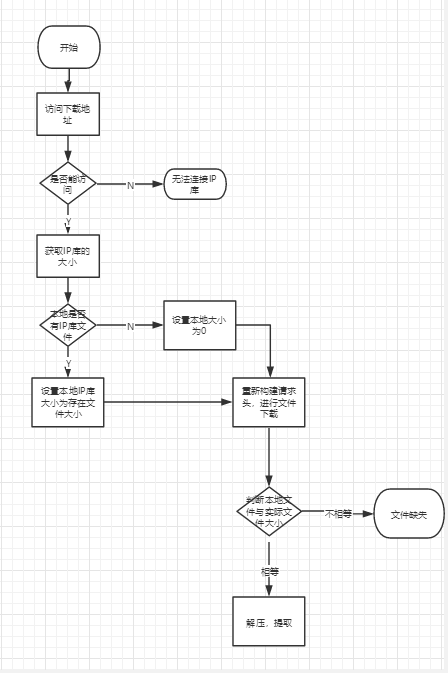
0x01
首先访问地址获取文件的大小
1 | req = requests.get(url=url, stream=True, verify=False, headers={"User-Agent": self.user_agent}) |
2 | if req.status_code == 200: |
3 | total_size = int(req.headers['Content-Length']) #获取文件的大小 |
0x02
然后判断本地是否存在这个文件,定义本地文件的大小,从而找到续传的起始字节
1 | if os.path.exists(os.path.join(os.getcwd(), 'dbs', 'GeoLite2-City.tar.gz')): |
2 | temp_size = os.path.getsize(os.path.join(os.getcwd(), 'dbs', 'GeoLite2-City.tar.gz')) |
3 | else: |
4 | temp_size = 0 |
0x03
下面就是最重要的部分,重新请求头,并设置获取文件的起始字节
1 | |
2 | headers = {"User-Agent": self.user_agent, 'Range': 'bytes=%d-' % temp_size} |
3 | re_req = requests.get(url, stream=True, verify=False, headers=headers) |
其中说下Http请求头中的
Range字段,这个实现断点续传的关键
Range: bytes=start-end例如
Range: bytes=10- :第10个字节及最后个字节的数据
Range: bytes=40-100 :第40个字节到第100个字节之间的数据.
注意,这个表示[start,end],即是包含请求头的start及end字节的,所以,下一个请求,应该是上一个请求的[end+1, nextEnd]
0x04
最后判断文件的大小是否和远端文件大小相等,如果相等进行解压、提取,这部分就包含文件解压,剪切的操作,
1 | if temp_size == total_size: |
2 | 4try: |
3 | 44#文件操作 |
4 | except: |
5 | raise FileNotFoundError('文件解压失败') |
整体代码
1 | |
2 | def __download_and_tar_geolite(self, url='https://geolite.maxmind.com/download/geoip/database/GeoLite2-City.tar.gz'): |
3 | req = requests.get(url=url, stream=True, verify=False, headers={"User-Agent": self.user_agent}) |
4 | if req.status_code == 200: |
5 | total_size = int(req.headers['Content-Length']) |
6 | if os.path.exists(os.path.join(os.getcwd(), 'dbs', 'GeoLite2-City.tar.gz')): |
7 | temp_size = os.path.getsize(os.path.join(os.getcwd(), 'dbs', 'GeoLite2-City.tar.gz')) |
8 | else: |
9 | temp_size = 0 |
10 | headers = {"User-Agent": self.user_agent, 'Range': 'bytes=%d-' % temp_size} |
11 | re_req = requests.get(url, stream=True, verify=False, headers=headers) |
12 | with open(os.path.join(os.getcwd(), 'dbs', 'GeoLite2-City.tar.gz'), 'ab') as f: |
13 | for chuck in re_req.iter_content(chunk_size=1024): |
14 | if chuck: |
15 | temp_size += len(chuck) |
16 | f.write(chuck) #文件保存 |
17 | f.flush() |
18 | done = int(50 * temp_size / total_size) |
19 | sys.stdout.write( |
20 | "正在进行数据库下载(不要结束程序):[%s%s] %d%%" % ( |
21 | '█' * done, ' ' * (50 - done), 100 * temp_size / total_size)) |
22 | sys.stdout.flush() |
23 | print() # 避免上面\r 回车符 |
24 | if temp_size == total_size: |
25 | try: |
26 | file = tarfile.open(os.path.join(os.getcwd(), 'dbs', 'GeoLite2-City.tar.gz')) |
27 | file.extractall(path=os.path.join(os.getcwd(), 'dbs')) #文件解压 |
28 | walk = os.listdir(os.path.join(os.getcwd(), 'dbs')) |
29 | for i in walk: |
30 | if 'GeoLite2-City_' in i: |
31 | src_path = os.path.join(os.getcwd(), 'dbs', i, 'GeoLite2-City.mmdb') |
32 | des_path = os.path.join(os.getcwd(), 'dbs') |
33 | shutil.move(src_path, des_path) #文件移动 |
34 | break |
35 | file.close() |
36 | return True |
37 | except: |
38 | raise FileNotFoundError('文件操作失败') |
39 | else: |
40 | raise Exception('文件缺失') |
41 | |
42 | else: |
43 | raise ConnectionError('无法连接数据库') |